
The Cloudflow development process
To understand the value that Cloudflow offers, let’s break down the typical design-develop-test-package-deploy lifecycle of an application and see how Cloudflow helps at each stage to accelerate the end-to-end process.
Designing Streaming Applications
When creating streaming applications, a large portion of the development effort goes into the mechanics of streaming. These include configuring and setting up connections to the messaging system, serializing and deserializing messages, setting up fault-recovery storage, and more. All of these mechanics must be addressed before you can finally add the most important and valuable part—business logic.
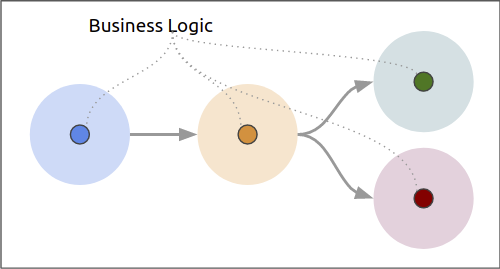
Cloudflow introduces a new component model, called Streamlets. The Streamlet model offers an abstraction to:
-
Identify the connections of a component as inlets and outlets, relieving you from setting up connections.
-
Attach the schema of the data for each connection, providing type safety at compile time, automatic serialization/deserialization, and avoiding potentially critical issues at deployment.
-
Provide an entry point for the business logic of the component, allowing you to focus on coding the most valuable business-specific logic.
Develop Focusing on Your Business Logic
In the current version, Cloudflow includes backend Streamlet implementations for Akka, Apache Spark - Structured Streaming, and Apache Flink.
Using these implementations you can write business logic in the native API of the backend.
Additionally, Cloudflow can be extended with new streaming backends.
The following table shows the current support for Java and Scala implementations for each runtime.
Streamlet API |
Scala |
Java |
Akka |
X |
X |
Flink |
X |
X |
Spark Structured Streaming |
X |
A Streamlet Example
Let’s take a look at the parts of a Streamlet in the following example:
class MovingAverageSparklet extends SparkStreamlet { (1)
val in = AvroInlet[Data]("in")
val out = AvroOutlet[Data]("out", _.key)
val shape = StreamletShape(in, out) (2)
override def createLogic() = new SparkStreamletLogic {
override def buildStreamingQueries = { (3)
val groupedData = readStream(in) (4)
.withColumn("ts", $"timestamp".cast(TimestampType))
.withWatermark("ts", "1 minutes")
.groupBy(window($"ts", "1 minute", "30 seconds"), $"key")
.agg(avg($"value").as("avg"))
val query = groupedData.select($"key", $"avg".as("value")).as[Data]
writeStream(query, out, OutputMode.Append).toQueryExecution
}
}
}| 1 | SparkStreamlet is the base class that defines Streamlet for the Apache Spark backend. |
| 2 | The StreamletShape defines the inlet(s) and outlet(s) of the Streamlet, each inlet/outlet is declared with its corresponding data type. |
| 3 | buildStreamletQueries is the entry point for the Streamlet logic. |
| 4 | The code provided is written in pure Spark Structured Streaming code, minus the boilerplate to create sessions, connections, checkpoints, etc. |
Akka Streams and Flink-based Streamlets follow the same pattern.
Compose the Application Flow with a Blueprint
Once you have developed components as Streamlets, you compose the application’s end-to-end flow by creating a blueprint.
The blueprint declares the streamlet instances that belong to an application and how each streamlet instance connects to the others.
The following example shows a simple Blueprint definition:
blueprint exampleblueprint {
streamlets { (1)
ingress = sensors.SparkRandomGenDataIngress
process = sensors.MovingAverageSparklet
egress = sensors.SparkConsoleEgress
}
topics { (2)
data {
producers = [ingress.out]
consumers = [process.in]
}
moving-averages {
producers = [process.out]
consumers = [egress.in]
}
}
}| 1 | streamlets section: declares instances from the streamlets available in the application (or its dependencies). |
| 2 | connections section: declares how the inlets/outlets of a streamlet should be connected. |
Note that the declaration of instances in the streamlets section supports component reuse by letting you define multiple instances of a streamlet, with potentially different configurations.
With the blueprint file in place, you can verify whether all components in the application are properly connected.
The verifyBlueprint function, is part of the sbt-cloudflow plugin.
The following shows example output from running sbt verifyBlueprint:
$ sbt verifyBlueprint
[info] Loading settings for project global-plugins from plugins.sbt ...
[info] Loading global plugins from /home/maasg/.sbt/1.0/plugins
[info] Loading settings for project spark-sensors-build from cloudflow-plugins.sbt,plugins.sbt ...
[info] Loading project definition from cloudflow/examples/spark-sensors/project
[info] Loading settings for project sparkSensors from build.sbt ...
[info] Set current project to spark-sensors (in build file:cloudflow/examples/spark-sensors/)
[info] Streamlet 'sensors.MovingAverageSparklet' found
[info] Streamlet 'sensors.SparkConsoleEgress' found
[info] Streamlet 'sensors.SparkRandomGenDataIngress' found
[success] /cloudflow/examples/spark-sensors/src/main/blueprint/blueprint.conf verified.The verification uses the schema information provided by the blueprint to check that all connections between streamlets are compatible. Once the blueprint verification succeeds, you know that the components of your streaming application can talk to each other. After verification, you can run the complete application.
The verification task is usually performed as a pre-requisite of other tasks, like runLocal or buildApp that we see next. While it’s possible to run it independently as shown here, it is most often used indirectly as part of those larger build tasks.
|
Test Locally Using the Sandbox
Cloudflow comes with a local execution mode called sandbox. The sandbox instantiates all streamlets of an application’s blueprint with their connections in a single, local JVM.
See the sandbox in action in the following screencast.
$>sbt
sbt>runLocal
...
[info] Streamlet 'carly.aggregator.CallAggregatorConsoleEgress' found
[info] Streamlet 'carly.aggregator.CallRecordGeneratorIngress' found
[info] Streamlet 'carly.aggregator.CallStatsAggregator' found
[success] /cloudflow/examples/call-record-aggregator/call-record-pipeline/src/main/blueprint/blueprint.conf verified.
┌──────────────┐ ┌──────────────┐ ┌───────────┐
│cdr-generator1│ │cdr-generator2│ │cdr-ingress│
└───────┬──────┘ └──────┬───────┘ └─────┬─────┘
│ │ │
└─────────┐ │ ┌─────────┘
│ │ │
v v v
┌────────────────────────┐
│[generated-call-records]│
└────────────┬───────────┘
│
v
┌─────┐
│split│
└─┬─┬─┘
│ │
│ └───────────┐
│ └┐
v │
┌────────────────────┐ │
│[valid-call-records]│ │
└─────────┬──────────┘ │
│ │
v │
┌──────────────┐ │
│cdr-aggregator│ │
└─┬────────────┘ │
│ │
v v
┌───────────────────────┐ ┌──────────────────────┐
│[aggregated-call-stats]│ │[invalid-call-records]│
└────────────┬──────────┘ └───────┬──────────────┘
│ │
v v
┌──────────────┐ ┌────────────┐
│console-egress│ │error-egress│
└──────────────┘ └────────────┘
---------------------------- Streamlets per project ----------------------------
spark-aggregation - output file: file:/tmp/cloudflow-local-run7107015168807762297/spark-aggregation-local.log
cdr-aggregator [carly.aggregator.CallStatsAggregator]
cdr-generator1 [carly.aggregator.CallRecordGeneratorIngress]
cdr-generator2 [carly.aggregator.CallRecordGeneratorIngress]
akka-java-aggregation-output - output file: file:/tmp/cloudflow-local-run7107015168807762297/akka-java-aggregation-output-local.log
console-egress [carly.output.AggregateRecordEgress]
error-egress [carly.output.InvalidRecordEgress]
akka-cdr-ingestor - output file: file:/tmp/cloudflow-local-run7107015168807762297/akka-cdr-ingestor-local.log
cdr-ingress [carly.ingestor.CallRecordIngress]
- HTTP port [3000]
split [carly.ingestor.CallRecordSplit]
--------------------------------------------------------------------------------
------------------------------------ Topics ------------------------------------
[aggregated-call-stats]
[generated-call-records]
[invalid-call-records]
[valid-call-records]
--------------------------------------------------------------------------------
----------------------------- Local Configuration -----------------------------
No local configuration provided.
--------------------------------------------------------------------------------
------------------------------------ Output ------------------------------------
Pipeline log output available in folder: /tmp/cloudflow-local-run7107015168807762297
--------------------------------------------------------------------------------
Running call-record-aggregator
To terminate, press [ENTER]The sandbox provides you with a minimalistic operational version of the complete application. Use it to exercise the functionality of the application end-to-end and verify that it behaves as expected. You get a blazing fast feedback loop for the functionality you are developing—removing the need to go through the full package, upload, deploy, and launch process on a remote cluster.
Publishing the Application Artifacts
Once you are confident that the application functions as expected, you can build and publish its artifacts. Cloudflow applications are packaged as Docker images that contain the necessary dependencies to run the different streamlets on their respective backends. Depending on the project structure, this process will generate one or more Docker images, at least one for each runtime used in the application.
Those images get published to the Docker repository of your choice, which must be configured in the project.
The process of building the application creates and publishes those Docker images.
The final result is an application descriptor encoded as a JSON file that can be used with the kubectl Cloudflow plugin to deploy the application to a cluster.
The buildApp task in the sbt-cloudflow plugin loads, verifies, creates and publishes the Docker images, and finally generates the JSON descriptor that we can use to deploy the application.
The following abridged example shows the different stages that you can observe in the output of this task.
$ sbt buildApp
... (1)
[info] Set current project to root (in build file:/cloudflow/examples/call-record-aggregator/)
[info] Streamlet 'carly.output.AggregateRecordEgress' found
[info] Streamlet 'carly.output.InvalidRecordEgress' found
[info] Streamlet 'carly.ingestor.CallRecordIngress' found
[info] Streamlet 'carly.ingestor.CallRecordSplit' found
[info] Streamlet 'carly.ingestor.CallRecordStreamingIngress' found
... (2)
[success] /cloudflow/examples/call-record-aggregator/call-record-pipeline/src/main/blueprint/blueprint.conf verified.
... (3)
[info] Sending build context to Docker daemon 51.97MB
[info] Step 1/4 : FROM lightbend/akka-base:2.0.10-cloudflow-akka-2.6.6-scala-2.12
[info] ---> bbcdde34a60a
[info] Step 2/4 : USER 185
[info] Successfully built dc0b6c01246e
[info] Tagging image dc0b6c01246e with name: eu.gcr.io/my-gcp-project/akka-cdr-ingestor:475-2cd83d8
...
[info] Successfully built and published the following image:
[info] eu.gcr.io/my-gcp-project/akka-cdr-ingestor:475-2cd83d8
[info] 57ceaacf8169: Pushed
... (4)
[success] Cloudflow application CR generated in /cloudflow/examples/call-record-aggregator/target/call-record-aggregator.json
[success] Use the following command to deploy the Cloudflow application:
[success] kubectl cloudflow deploy /cloudflow/examples/call-record-aggregator/target/call-record-aggregator.json
[success] Total time: 129 s (02:09), completed Jun 24, 2020 12:58:46 PM| 1 | Project gets loaded |
| 2 | The application is validated by combining the info in the blueprint, streamlets, and schema information. |
| 3 | The Docker images are built and published |
| 4 | The application descriptor is generated in the /target folder of the project and we get a hint of the command to use for initialing the deployment |
Next, we see how to use the application descriptor to deploy the application to a cluster.
Deploy with kubectl Extensions for a YAML-less Experience
After testing and packaging, you are ready to deploy the application to a Cloudflow-enabled Kubernetes cluster. A Cloudflow-enabled Kubernetes cluster has Cloudflow installed as well as Spark and/or Flink, if your streamlets use them. In contrast with the usual YAML-full experience that typical K8s deployments require, Cloudflow uses the blueprint information and the streamlet definitions to auto-generate an application deployment.
Kafka is used by Cloudflow to connect streamlets together with the topology defined in a blueprint. If you intend to connect streamlets in this way, at least one Kafka cluster should be available before you install Cloudflow. Cloudflow may be used without Kafka (for example, when your application contains a single streamlet, or an Akka cluster), but if your team intends to connect streamlets together and not include Kafka connection information in each topic they define then it’s recommended to define a default Kafka cluster at install time.
Cloudflow also comes with a kubectl plugin that augments the capabilities of your local kubectl installation to work with Cloudflow applications.
You use your usual kubectl commands to auth against your target cluster.
Then, with the kubectl cloudflow plugin you can deploy and manage a Cloudflow application as a single logical unit.
$ kubectl cloudflow deploy /cloudflow/examples/call-record-aggregator/target/call-record-aggregator.jsonThis method is not only dev-friendly, but is also compatible with the typical CI/CD deployments. This allows you to take the application from dev to production in a controlled way.
Conclusion
As a developer, Cloudflow gives you a set of powerful tools to accelerate the application development process:
-
The Streamlet API let’s you focus on business value and use your knowledge of widely popular streaming runtimes, like Akka Streams, Apache Spark Structured Streaming, and Apache Flink to create full-fledged streaming applications.
-
The blueprint lets you easily compose your application with the peace of mind that a verification phase, informed by schema definitions, provides.
-
The sandbox lets you exercise the complete application in seconds, giving you a real-time feedback loop to speed up the debugging and validation phases.
And with a fully developed application, the kubectl cloudflow plugin gives you the ability to deploy and control the lifecycle of your application on an enabled K8s cluster.
Cloudflow takes away the pain of creating and deploying distributed applications on Kubernetes, speeds up your development process, and gives you full control over the operational deployment. In a nutshell, it gives you distributed application development super-powers on Kubernetes.