






Using Spark Streamlets
A Spark streamlet has the following responsibilities:
-
It needs to capture your stream processing logic.
-
It needs to publish metadata which will be used by the
sbt-cloudflowplugin to verify that a blueprint is correct. This metadata consists of the shape of the streamlet (StreamletShape) defined by the inlets and outlets of the streamlet. Connecting streamlets need to match on inlets and outlets to make a valid cloudflow topology, as mentioned previously in Composing applications using blueprints. Cloudflow automatically extracts the shapes from the streamlets to verify this match. -
For the Cloudflow runtime, it needs to provide metadata so that it can be configured, scaled, and run as part of an application.
-
The inlets and outlets of a
Streamlethave two functions:-
To specify to Cloudflow that the streamlet needs certain data streams to exist at runtime, which it will read from and write to, and
-
To provide handles inside the stream processing logic to connect to the data streams that Cloudflow provides. The
StreamletLogicprovides methods that take an inlet or outlet argument to read from or write to. These will be the specific data streams that Cloudflow has set up for you.
-
The next sections will go into the details of defining a Spark streamlet:
-
defining inlets and outlets
-
creating a streamlet shape from the inlets and outlets
-
creating a streamlet logic that uses the inlets and outlets to read and write data
Inlets and outlets
A streamlet can have one or more inlets and outlets.
Cloudflow offers classes for Inlets and Outlets based on the
codec of the data they manipulate.
Currently, Cloudflow supports Avro and hence the classes are named AvroInlet and AvroOutlet.
Each outlet also allows the user to define a partitioning function that will be used to partition the data.
StreamletShape
The StreamletShape captures the connectivity and compatibility details of a Spark-based streamlet.
It captures which—and how many—inlets and outlets the streamlet has.
The sbt-cloudflow plugin extracts—amongst other things—the shape from the streamlet that it finds on the classpath.
This metadata is used to verify that the blueprint connects the streamlets correctly.
Cloudflow offers an API StreamletShape to define various shapes with inlets and outlets. Each inlet and outlet can be defined separately with specific names.
The outlet also allows for the definition of a partitioning function.
This partitioning function is used to distribute the output data among partitions.
When you build your own Spark streamlet, you need to define the shape. You will learn how to do this in Building a Spark streamlet. The next section describes how the SparkStreamletLogic captures stream processing logic.
SparkStreamletLogic
The stream processing logic is captured in a SparkStreamletLogic, which is an abstract class.
The SparkStreamletLogic provides methods to read and write data streams, and provides access to the configuration of the streamlet, among other things.
A SparkStreamletLogic must setup one or more Structured Streaming Queries, represented by a collection of StreamingQuerys, through the method buildStreamingQueries.
These jobs will be run by the run method of SparkStreamlet to produce a StreamletExecution. A StreamletExecution is a simple class to manage a collection of StreamingQuerys.
The SparkStreamletLogic is only constructed when the streamlet is run, so it is safe to put instance values and variables in it that you would like to use when the streamlet is running. Note that the Streamlet is created for extracting metadata and hence no instance values should be put inside a streamlet.
SparkStreamletContext
The SparkStreamletContext provides the necessary context under which a streamlet runs.
It contains the following context data and contracts:
-
An active
SparkSessionto run Spark streaming jobs. -
The Typesafe
Configloaded from the classpath through aconfigmethod, which can be used to read configuration settings. -
The name used in the blueprint for the specific instance of this streamlet being run.
-
A function
checkpointDirwhich returns a directory on a persistent storage where checkpoints can be safely kept, making them available across restarts.
Lifecycle
In general terms, when you publish and deploy a Cloudflow application, each streamlet definition becomes a physical deployment as one or more Kubernetes artifacts. In the case of Spark streamlets, each streamlet is submitted as a Spark application through the Spark Operator as a Spark Application resource. Upon deployment, it becomes a set of running pods, with one pod as a Spark Driver and n-pods as executors, where n is the scale factor for that streamlet.
|
The Spark Operator is a Kubernetes operator dedicated to managing Spark applications. |
The Spark Operator takes care of monitoring the streamlets and is responsible for their resilient execution, like restarting the Spark application in case of failure.
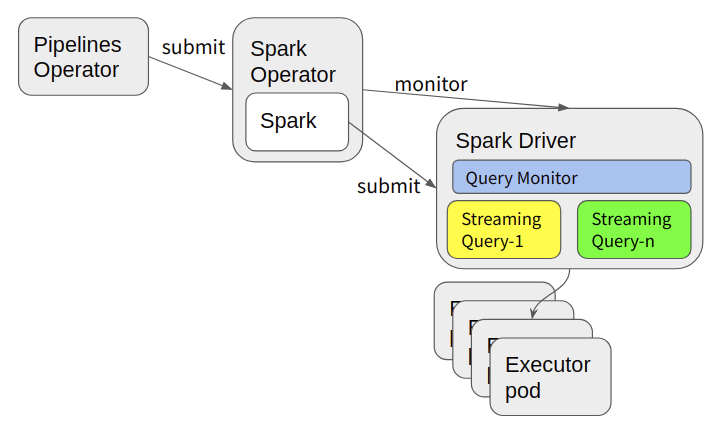
In the Spark streamlet deployment model shown above, we can visualize the chain of delegation involved in the deployment of a Spark streamlet:
-
The Cloudflow Operator prepares a Custom Resource describing the Spark streamlet and submits it to the Spark Operator.
-
The Spark Operator processes the Custom Resource and issues the deployment of a Spark driver pod.
-
The Spark Driver then requests executor resources from Kubernetes to deploy the distributed processing.
-
Finally, if and when resources are available, the Spark-bound executors start as Kubernetes pods. The executors are the components tasked with the actual data processing, while the Spark driver serves as coordinator of the (stream) data process.
In this architecture, the Spark driver runs the Cloudflow-specific logic that connects the streamlet to our managed data streams, at which point the streamlet starts consuming from inlets. The streamlet advances through the data streams that are provided on inlets and writes data to outlets.
If you make any changes to the streamlet and deploy the application again, the existing Spark applications will be stopped, and the new version will be started to reflect the changes. It could be that Spark streamlets are restarted in other ways, for instance by administrators.
This means that a streamlet can get stopped, started or restarted at any moment in time. The next section about message delivery semantics explains the options that are available for how to continue processing data after a restart.
Message delivery semantics
The message delivery semantics provided by Spark streamlets are determined by the guarantees provided by the underlying Spark sources and sinks used in the streamlet. Recall that we defined the different message delivery guarantees in Message delivery semantics.
Let’s consider the following types of streamlets as forming a topology as illustrated in Ingress-Processor-Egress Streamlets:
-
an ingress, a streamlet that reads from an external streaming source and makes data available to the pipeline
-
a processor, a streamlet that has an inlet and an outlet - it does domain logic processing on data that it reads and passes the processed data downstream
-
an egress, a streamlet that receives data on its inlet and writes to an external sink
The following sections will use these types of streamlets for describing message delivery semantics.

Message delivery semantics of Spark-based ingresses
Spark-based ingresses use a Structured Streaming source to obtain data from an external streaming source and provide it to the Cloudflow application. In this case, message delivery semantics are dependent on the capabilities of the source. In general, streaming sources deemed resilient will provide at-least-once semantics in a Pipeline application.
Refer to the The Structured Streaming Programming Guide or to Stream Processing with Apache Spark for more detailed documentation about your streaming source of choice.
Message delivery semantics of spark-based processors
A Spark based processor is a streamlet that receives and produces data internal to the Cloudflow application. In this scenario, processors consume data from inlets and produce data to outlets using Kafka topics as the underlying physical implementation.
At the level of a Spark-based processor, this translates to using Kafka sources and sinks. Given that Kafka is a reliable data source from the Structured Streaming perspective, the message delivery semantics are considered to be at-least-once.
|
Testing At-Least-Once Message Delivery
Bundled with our examples, |
Message delivery semantics of spark-based egresses
The message delivery guarantees of a Spark-based egress are determined by the combination of the Kafka-based inlet and the target system where the egress will produce its data.
The data provided to the egress is delivered with at-least-once semantics. The egress is responsible to reliably produce this data to the target system. The overall message delivery semantics of the Pipeline will depend on the reliability characteristics of this egress.
In particular, it is possible to 'upgrade' the end-to-end message delivery guarantee to effectively-exactly-once by making the egress idempotent and ensuring that all other streamlets used provide at-least-once semantics.
For this purpose, we could use Structured Streaming’s deduplication feature, or use a target system able to preserve uniqueness of primary keys, such as an RDBMS.
Message delivery semantics and the Kafka retention period
The at-least-once delivery is guaranteed within the Kafka retention configuration. This retention is a configuration proper to the Kafka brokers that dictates when old data can be evicted from the log. If a Spark-based processor is offline for a longer time than the configured retention, it will restart from the earliest offset available in the corresponding Kafka topic, which might silently result in data loss.
Reliable restart of stateful processes
In a Pipeline application, it’s possible to use the full capabilities of Structured Streaming to implement the business logic required in a streamlet.
This includes stateful processing, from time-based aggregations to arbitrary stateful computations that use mapGroupsWithState and flatMapGroupsWithState.
All stateful processing relies on snapshots and a state store for the bookkeeping of the offsets processed and the computed state at any time.
In Cloudflow, this state store is deployed on Kubernetes using Persistent Volume Claims (PVCs) backed by a storage class that allows for access mode ReadWriteMany.
PVCs are automatically provisioned for each Cloudflow application. The volumes are claimed for as long as the Pipeline application is deployed, allowing for seamless re-deployment, upgrades, and recovery in case of failure.
We can use the managed storage to safely store checkpoint data.
Checkpoint information is managed by Cloudflow for all streamlets that use the context.writeStream method.
In case we need a directory to store state data that must persist across restarts of the streamlet, we can obtain a directory mounted on the managed PVC using the context.checkpointDir(name) method.
This method takes as parameter the name of the directory we want for our particular use and returns a path to a persistent storage location.
When implementing egresses that use Spark’s Structured Streaming sinks, ensure that each query uses a unique name for its checkpointDir
In Example of the use of checkpointDir, we can see the use of the checkpointDir method to provide the checkpoint directory to a console-based egress.
checkpointDir override def buildStreamingQueries =
readStream(in).writeStream
.format("console")
.option("checkpointLocation", context.checkpointDir("console-egress"))
.outputMode(OutputMode.Append())
.start()
.toQueryExecution|
Storage Size is Currently Fixed
Please note that — currently — the volume size allocated for storage is fixed per Cloudflow platform deployment. |
Checkpoints and application upgrades
The storage of snapshots and state has certain impact on the upgradability of the Spark-based components. Once a state representation is deployed, the state definition (schema) may not change.
Upgrading an application that uses stateful computation requires planning ahead of time to avoid making incompatible changes that prevent recovery using the saved state. Significant changes to the application logic, addition of sources, or changes to the schema representing the state are not allowed.
For details on the degrees of freedom and upgrade options, please refer to the Structured Streaming documentation.